Code database with an implementation of MSE-CNN [1]. Besides the code, the dataset and coefficients obtained after training are provided.
- MSE-CNN Implementation
- 1. Introduction
- 2. Theorectical Background
- 2.1 Partitioning in VVC
- 2.2 MSE-CNN
- 2.2.1 Architecture
- 2.2.2 Loss Function
- 2.2.3 Training
- 2.2.4 Implementation remarks
- 3. Dataset
- 4. Results
- 4.1 F1-score, Recall and Precision with test data
- 4.2 Confusion matrices
- 4.2.1 Stages 2 and 3
- 4.2.2 Stages 4 and 5
- 4.2.3 Stage 6
- 4.3 Y-PSNR, Complexity Reduction and Bitrate with test data
- 5. Relevant Folders and files
- 5.1 Folders
- 5.2 Files in src folder
- 6. Installation of dependencies
- Requirements
- Package Distributions
- 7. Demo
- 8. Contributions
- 9. License
- 10. TODO
- 11. References
1. Introduction
The emergence of new technologies that provide creative audiovisual experiences, such as 360-degree films, virtual reality, augmented reality, 4K, 8K UHD, 16K, and also with the rise of video traffic on the web, shows the current demand for video data in the modern world. Because of this tension, Versatile Video Coding (VVC) was developed due to the the necessity for the introduction of new coding standards. Despite the advancements achieved with the introduction of this standard, its complexity has increased very much. The new partitioning technique is responsible for majority of the increase in encoding time. This extended duration is linked with the optimization of the Rate-Distortion cost (RD cost). Although VVC offers higher compression rates, the complexity of its encoding is high.

In light of this, the Multi-Stage Exit Convolutional Neural Nework (MSE-CNN) was developed. This Deep Learning-based model is organised in a sequential structure with several stages. Each stage, which represents a different partition depth, encompasses a set of layers for extracting features from a Coding Tree Unit (CTU) and deciding how to partition it. Instead of using recursive approaches to determine the optimal way to fragment an image, this model allows VVC to estimate the most appropriate way of doing it. This work presents a model of the MSE-CNN that employs training procedures distinct from the original implementation of this network, as well as the ground-thruth to train and validate the model and an interpretation of the work done by the MSE-CNN’s original creators.

2. Theorectical Background
2.1 Partitioning in VVC
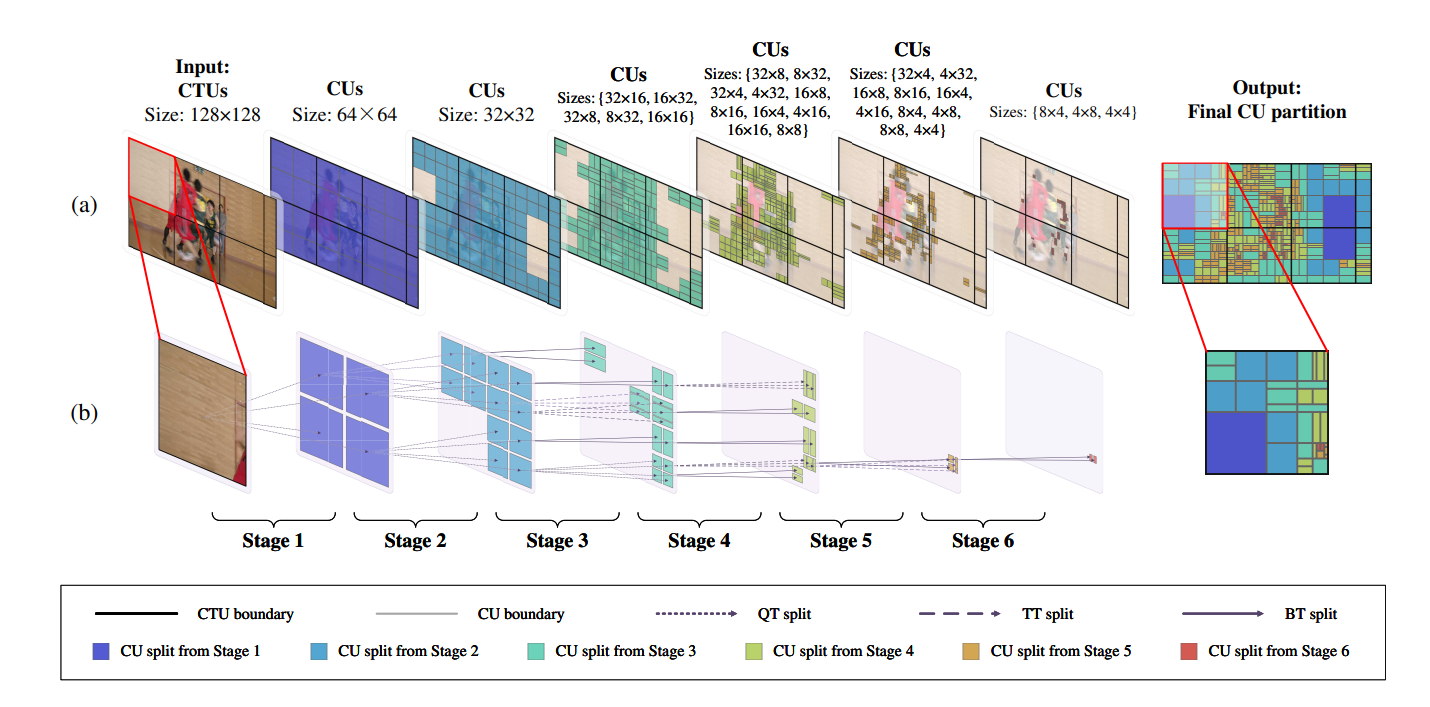
The key objective of partitioning is to divide frames into pieces in a way that results in a reduction of the RD cost. To achieve a perfect balance of quality and bitrate, numerous image fragments combinations must be tested, which is computationally expensive. Due to the intensive nature of this process, a high compression rate can be attained. Partitioning contributes heavily to both the complexity and compression gains in VVC. H.266 (VVC), organize a video sequence in many frames that are divided into smaller pieces. First, pictures are split into coding tree units (CTUs), and then they are divided into coding units (CUs). For the luma channel, the largest CTU size in VVC is 128x128 and the smallest is 4x4. In VVC, a quad-tree (QT) is initially applied to the CTUs in the first level, and then a quad-tree with nested multi-type tree (QMTT) is applied recursively.
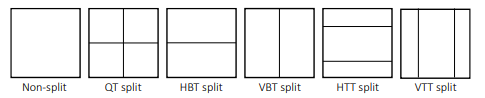
This innovation makes it possible to split CUs in different rectangle forms. Splitting a CU into:
- three rectangles with a ratio of 1:2:1 results in a ternary tree (TT), with the center rectangle being half the size of the original CU; when applied horizontally it is called a horizontal ternary tree (HTT), and vertical ternary tree (VTT) when it is done vertically.
- two rectangles results in a binary tree (BT)partition, a block with two symmetrical structures; like in the case of the TT, depending on the way the split is done, it can be called either a vertical binary tree (VBT) or a horizontal binary tree (HBT).
The association of BT and TT is named a multi-type tree (MTT). The introduction of BT and TT partitions enables the creation of various new types of forms, with heights and widths that can be a combination between 128, 64, 32, 16, 8 and 4. The increased number of possible CUs boosts the ability of the codec to fragment an image more efficiently, allowing better predictions and higher compressing abilities. Although this standard now have these advantages, as a downside it takes longer to encode.
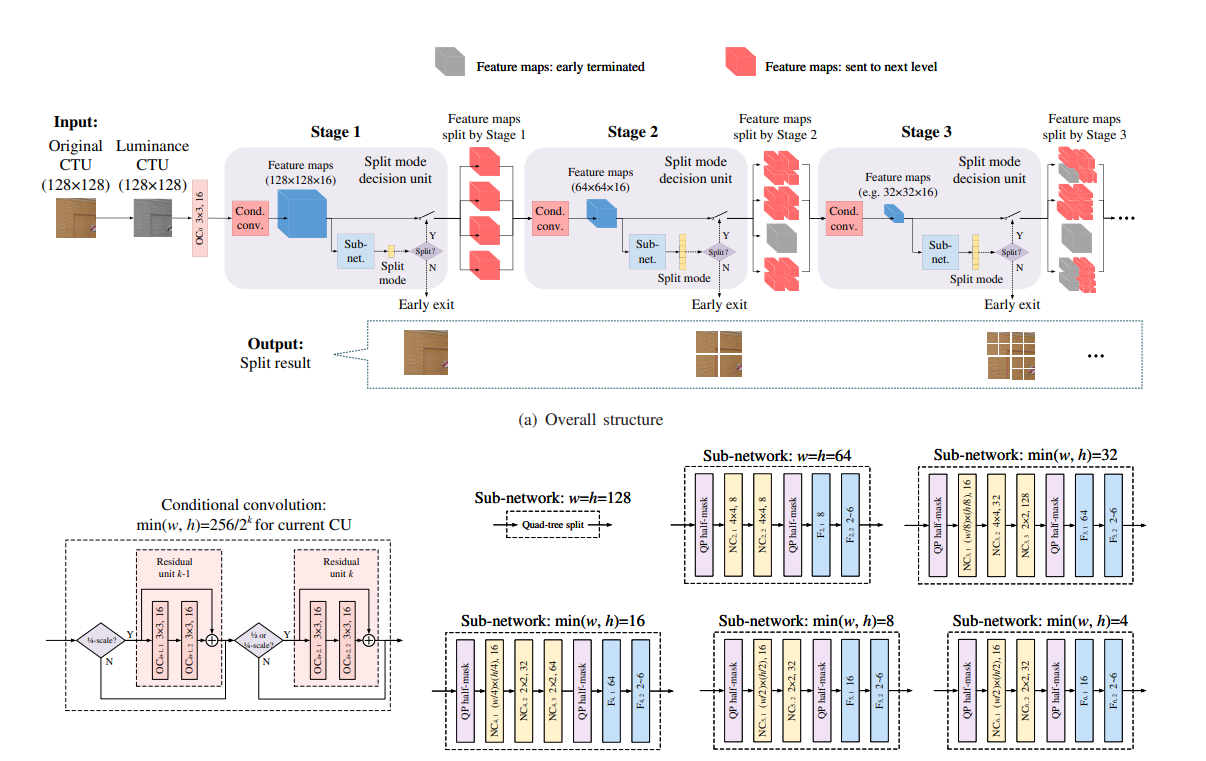
2.2 MSE-CNN
Multi-Stage Exit Convolutional Neural Network (MSE-CNN) is a DL model that seeks to forecast CUs in a waterfall architecture (top-down manner), it integrates . This structure takes a CTU as input, extracts features from it, splits the CU into one of at most six possible partitions (Non-split, QT, HBT, VBT, HTT, and VTT), and then sends it to the next stage. This model has CTUs as inputs in the first stage, either in the chroma or luma channel, and feature maps in the subsequent stages. Furthermore, it generates feature maps and a split decision at each level. In the event that one of the models returns the split decision as Non-Split, the partitioning of the CU is ended immediately.
Note: Details about how to load model coefficients can be found here.
2.2.1 Architecture
This model is composed by the following blocks:
- Initially, this model adds more channels to the input of this network to create more features from it; this is accomplished by utilising simple convolutional layers.
- To extract more characteristics from the data, the information is then passed through a series of convolutional layers; these layers were named Conditional Convolution.
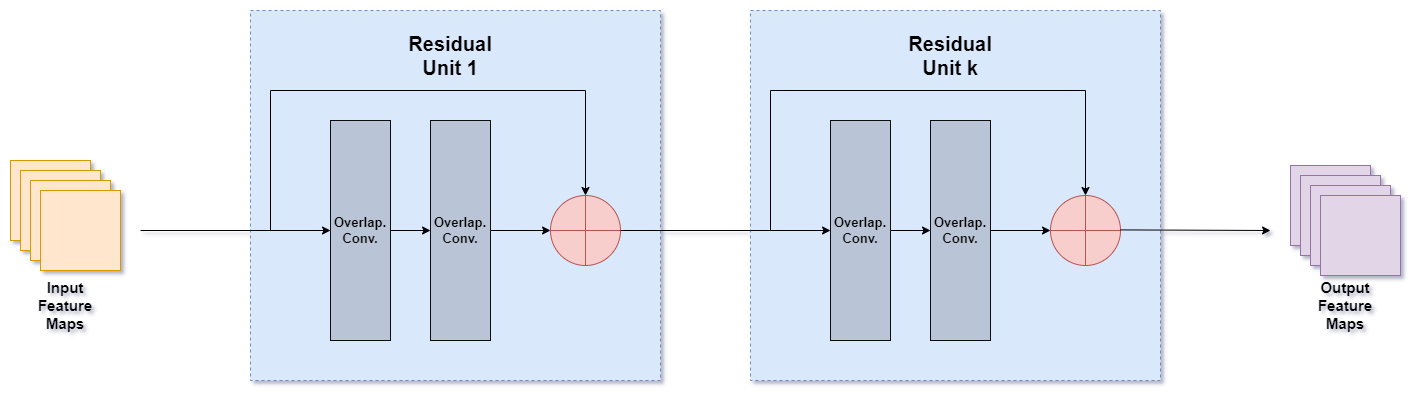
- At the end, a final layer is employed to determine the optimal manner of partitioning the CU. This layer is a blend of fully connected and convolutional layers.
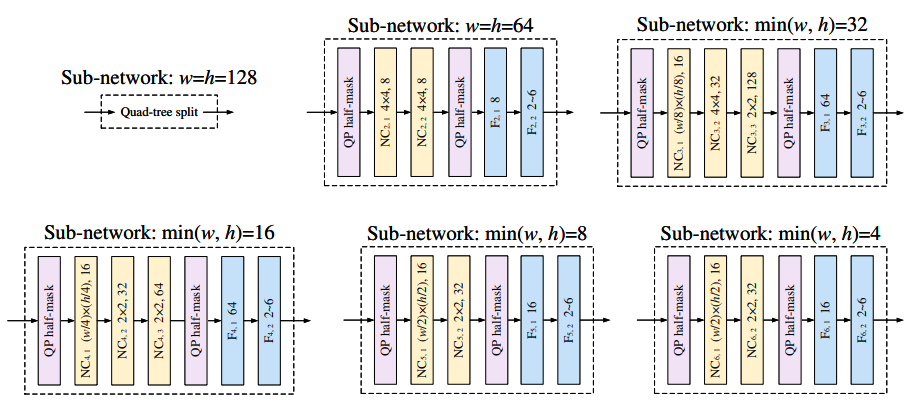
Note: For more details regarding these layers check [1]
2.2.2 Loss Function
The loss developed for the MSE-CNN is the result of two other functions, as defined in the following expression:
$$ L = L_{CE}+\beta L_{RD}$$
In the above equation, $\beta$ is a real number to adjust the influence of the $L_{RD}$ loss. The first member of this loss function is a modified Cross-Entrotopy loss, developed to solve imbalanced dataset issues:
$$L_{CEmod} = -\frac{1}{N}\sum_{n=1}^N \sum_{m\varepsilon Partitions}(\frac{1}{p_m})^\alpha y_{n, m}\log(\hat{y}_{n, m})$$
Concerning the second member of the MSE-CNN loss function, this constituent gives the network the ability to also make predictions based on the RD Cost.
$$L_{RD} = \frac{1}{N}\sum_{n=1}^N \sum_{m\varepsilon Partitions}\hat{y}_{n, m}\frac{r_{n, m}}{r_{n, min}}-1$$
In the above equation, the RD costs $r_{n, m}$ uses the same notation for "n" and "m" as the previous equation. Regarding $r_{n ,min}$, it is the minimal RD cost for the nth CU among all split modes and $$\frac{r_{n, m}}{r_{n, min}} - 1$$ is a normalised RD cost. As a relevant note, $r_{n, min}$ is equal to the RD cost of the best partition mode. Consequently, the result of
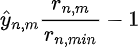
ensures that CU's partitions with greater erroneously predicted probability values or greater RD cost values $r_{n, m}$ are more penalised. In $\frac{r_{n, m}}{r_{n, min}} - 1$, the ideal partition has a normalised RD cost of zero, but the other partitions do not. Therefore, the only way for the loss to equal zero is if the probability for all other modes also equals zero. Consequently, the learning algorithm must assign a greater probability to the optimal split mode while reducing the probabilities for the rest. Experimentally it was verified that this function wasn't able to contribute to the training of the MSE-CNN, this contradicted the remarks made in [1].
2.2.3 Training
The strategy used to train the MSE-CNN was very similar to the one used in [1]. The first parts of the model to be trained were the first and second stages, in which 64x64 CUs were passed through the second depth. Afterwards, transfer learning was used to pass certain coefficients of the second stage to the third. Then, the third stage was trained with 32x32 CUs flowing through it. After this step, a similar process was done to the following stages. It is worth noting that, beginning with stage 4, various CUs forms are at the models' input. This means that these stages were fed different kinds of CUs.
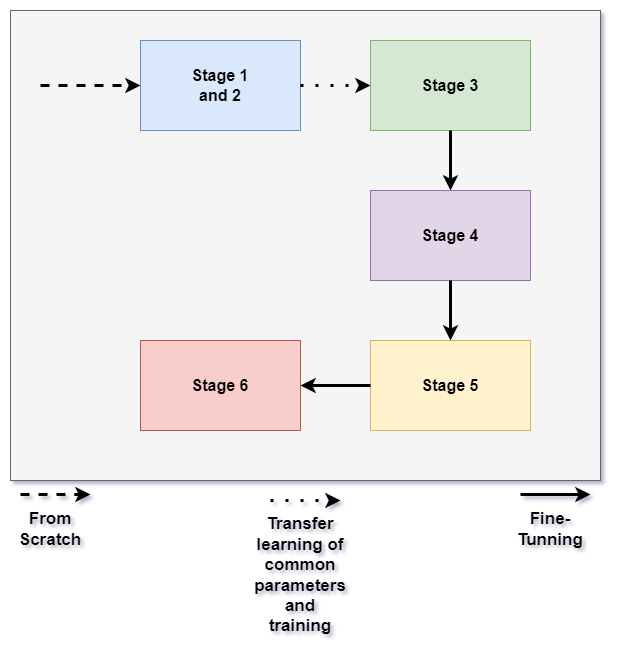
At the end of training, 6 models were obtained one for each partitioning depth in the luma channel. Although models for the luma and chroma channels could be created for all the shapes of CUs that are possible, rather than just for each depth, only six were trained for the sake of assessing the model behaviour in a simpler and more understandable configuration.
2.2.4 Implementation remarks
Due to the deterministic nature of the first stage, where CTUs are always partitioned with a QT, it was implemented together with the second stage. If it was done separately, the training for the first two stages would have to be done at the same time. Consequently, two distinct optimisers would need to be employed, which could result in unpredictable training behaviour.
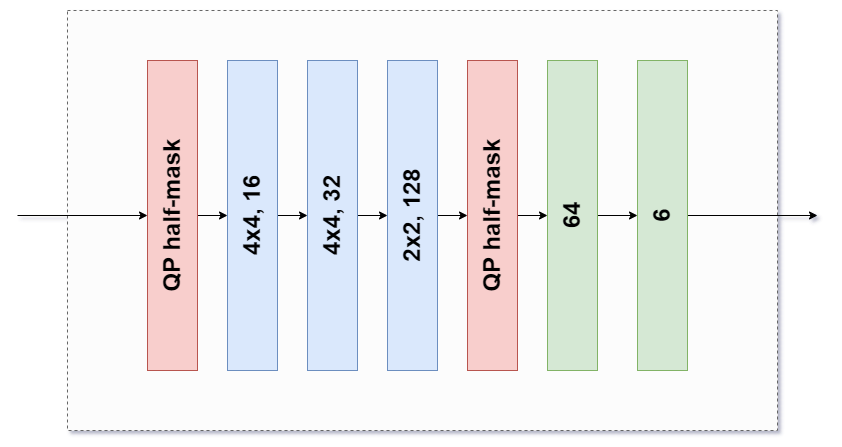
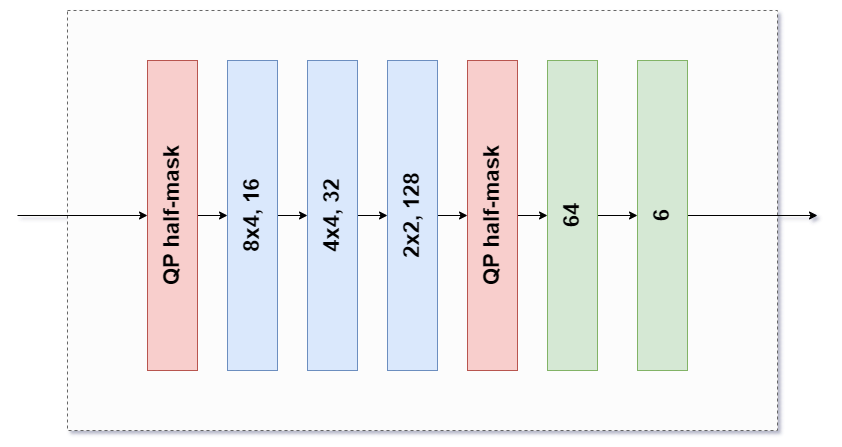
When implementing the sub-networks on code, those that were meant to cater for varying CU sizes were further implemented separately. For example, in the case of the sub-network utilised when the minimum width or height is 32, two variants of the first two layers were built. This was done because 64x32 and 32x32 CUs can flow across this block. Because of this, the first two layers were implemented separately from the entire block. Then, they were used in conjunction with the remaining layers based on the dimensions of the input CU. The same procedures were followed for the other types of sub-networks.
When the network was being trained, some of the RD costs from the input data had very high values. Consequently, the RD loss function value skyrocketed, resulting in extremely huge gradients during training. As a result, the maximum RD cost was hard coded at $10^{10}$. This amount is large enough to be more than the best partition's RD cost and small enough to address this issue.
3. Dataset
Please see this page to understand better the dataset and also access it. To see example data go to follow this.
4. Results
Since it was verified that the Rate-Distortion Loss. $L_{RD}$, could contribute for better results, the metrics presented here were obtained with a model trained only with the modified cross-entropy loss.
4.1 F1-score, Recall and Precision with test data
| Stage | F1-Score | Recall | Precision |
|---|---|---|---|
| Stage 2 | 0.9111 | 0.9111 | 0.9112 |
| Stage 3 | 0.5624 | 0.5767 | 0.5770 |
| Stage 4 | 0.4406 | 0.4581 | 0.4432 |
| Stage 5 | 0.5143 | 0.5231 | 0.5184 |
| Stage 6 | 0.7282 | 0.7411 | 0.7311 |
Results with weighted average for F1-score, recall and precision.
4.2 Confusion matrices
4.2.1 Stages 2 and 3
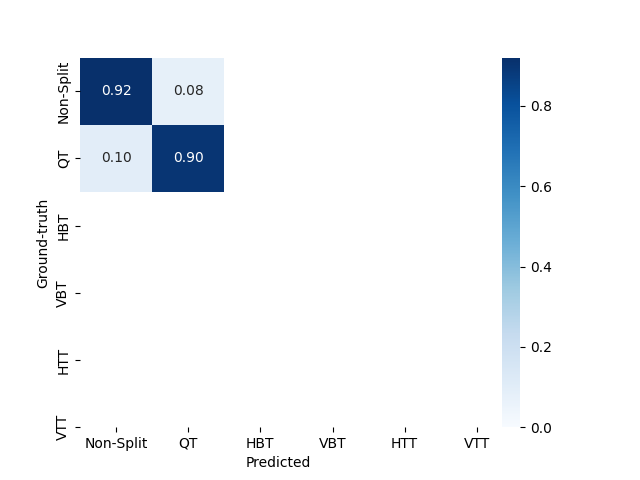
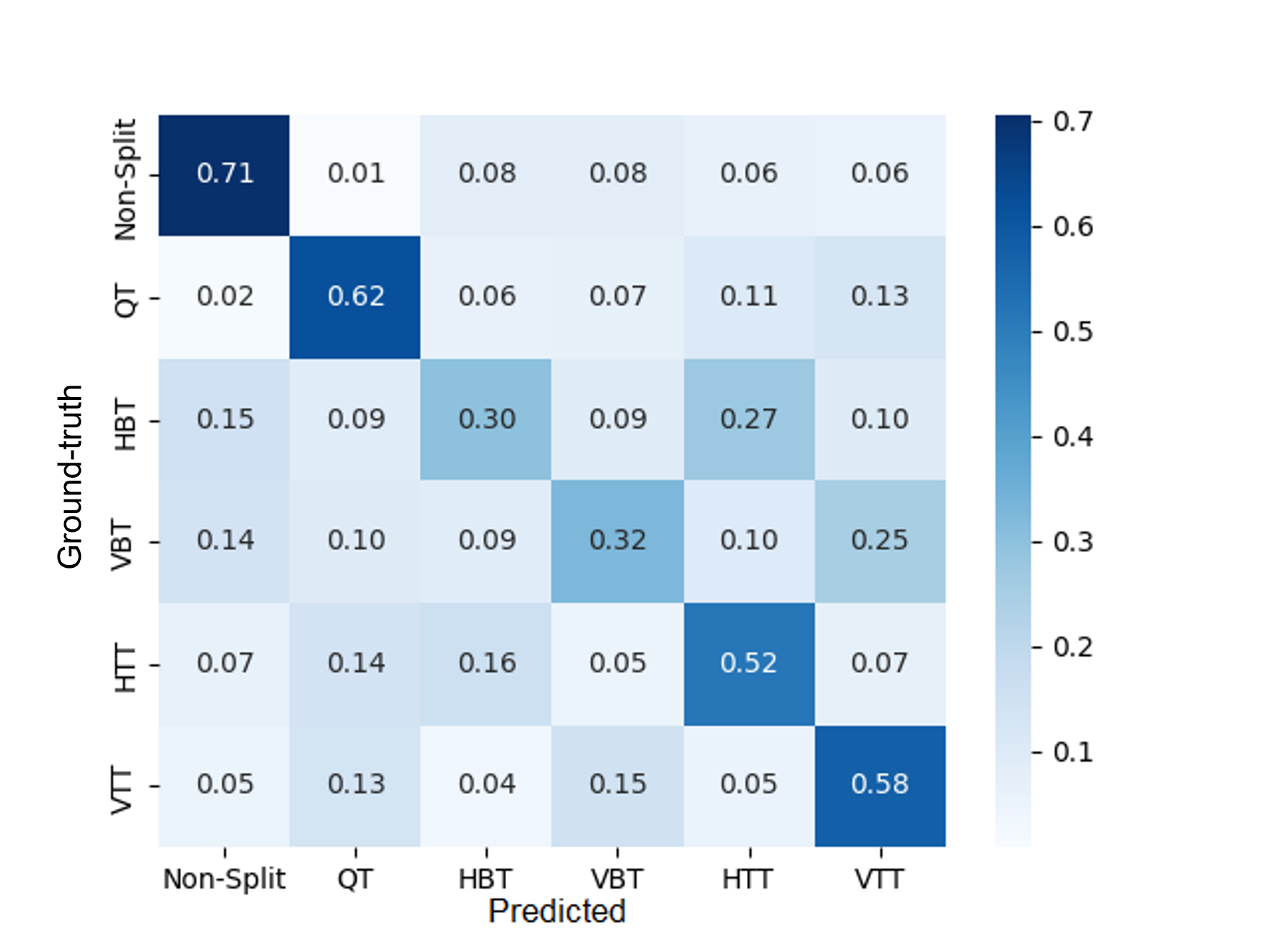
4.2.2 Stages 4 and 5
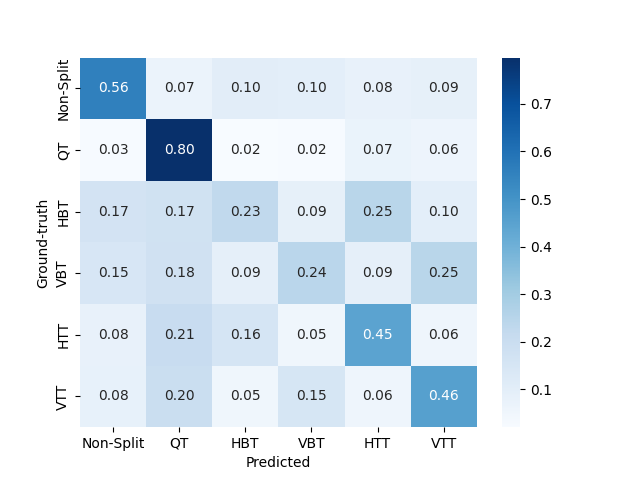
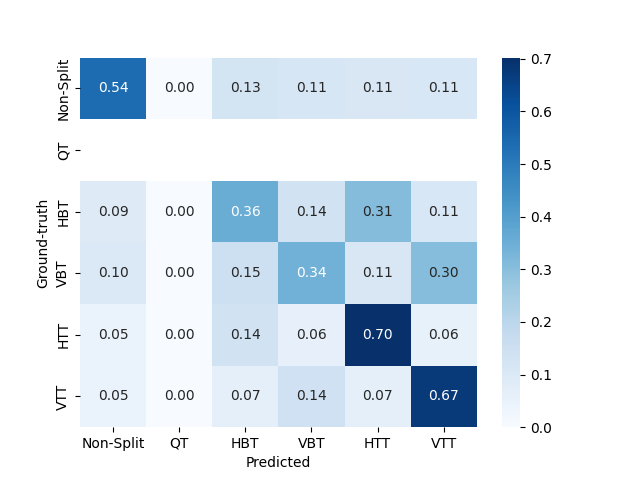
4.2.3 Stage 6
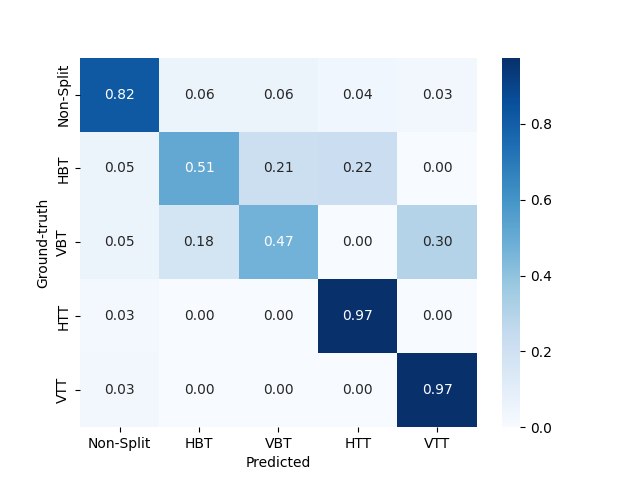
4.3 Y-PSNR, Complexity Reduction and Bitrate with test data
| Metric | VTM-7.0 | VTM-7.0+Model | Gain |
|---|---|---|---|
| Bitrate | 3810.192 kbps | 4069.392 kbps | 6.80% |
| Y-PSNR | 35.7927 dB | 35.5591 dB | -0.65% |
| Complexity | 1792.88 s | 1048.95 s | -41.49% |
These results were obtained with the "medium" configuration for the multi-thresholding method.
5. Relevant Folders and files
5.1 Folders
| Folder | Description |
|---|---|
| dataset | This folder contains all of the dataset and all of the data that was processed in order to obtain it |
| example_data | Here you can find some example data that it is used for the scripts in usefull_scripts folder |
| model_coefficients | The last coefficient obtained during training, as well as the best one in terms of the best F1-score obtained in testing data |
| src | Source code with the implementation of the MSE-CNN and also useful code and examples |
5.2 Files in src folder
| Files | Description |
|---|---|
| constants.py | Constant values used in other python files |
| custom_dataset.py | Dataset class to handle the files with the ground-thruth information, as well as other usefull classes to work together with the aforementioned class |
| dataset_utils.py | Functions to manipulate and process the data, also contains functions to interact with YUV files |
| msecnn.py | MSE-CNN and Loss Function classes implementation |
| train_model_utils.py | Usefull functions to be used during training or evaluation of the artificial neural network |
| utils.py | Other functions that are usefull not directly to the model but for the code implementation itself |
6. Installation of dependencies
In order to explore this project, it is needed to first install of the libraries used in it.
Requirements
For this please follow the below steps:
- Create a virtual environment to do install the libraries; follow this link in case you don't know how to do it; you possibly need to install pip, if you don't have it installed
- Run the following command: This will install all of the libraries references in the requirements.txt file.pip install -r requirements.txt
- When you have finished using the package or working on your project, you can deactivate the virtual environment: This command exits the virtual environment and returns you to your normal command prompt.deactivate
- Enjoy! :)
Package Distributions
- Locate the
distfolder in your project's root directory. This folder contains the package distributions, including the source distribution (*.tar.gzfile) and the wheel distribution (*.whlfile). - Install the package using one of the following methods:
- Install the source distribution: pip install dist/msecnn_raulkviana-1.0.tar.gz
- Install the wheel distribution: pip install dist/msecnn_raulkviana-1.0.whl
- Install the source distribution:
- Once the package is installed, you can import and use its functionalities in your Python code.
7. Demo
8. Contributions
Feel free to contact me through this email or create either a issue or pull request to contribute to this project ^^.
9. License
This project license is under the [MIT License](LICENSE).
10. TODO
| Task | Description | Status (d - doing, w - waiting, f- finished) |
|---|---|---|
| Implement code to test functions | Use a library, such as Pytest, to test some functions from the many modules developed | w |
11. References
[1] T. Li, M. Xu, R. Tang, Y. Chen, and Q. Xing, “DeepQTMT: A Deep Learning Approach for Fast QTMT-Based CU Partition of Intra-Mode VVC,” IEEE Transactions on Image Processing, vol. 30, pp. 5377–5390, 2021, doi: 10.1109/tip.2021.3083447. [2] R. K. Viana, “Deep learning architecture for fast intra-mode CUs partitioning in VVC,” Universidade de Aveiro, Nov. 2022.
